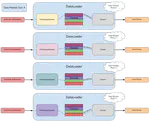
In this post, we will address the fundamental aspects of Torch’s Datasets and DataLoaders, considering an environment with Data, Pipeline and Tensor Parallelism and including functionalities to resume training after an interruption. We will present Nanosets, a custom dataset for LLM training at scale with Nanotron